

预测性维护的工程逻辑、技术体系与智能演进——从设备健康感知到AI驱动的主动运维决策

Redcoast2026-02-06
01 工业现实:为什么传统维护方式正在系统性失效
在流程工业、离散制造及连续化生产场景中,设备维护长期依赖两种模式:
- 事后维护:设备发生故障后再进行修复
- 定期维护:基于时间或运行周期进行计划检修
这两种模式在早期设备结构简单、生产节奏相对宽松的条件下尚可运转,但在当前工业环境中,逐步暴露出根本性问题:
- 装置规模扩大、系统高度耦合,单点故障可能引发连锁停机
- 连续化生产使非计划停机成本急剧上升
- 设备个体差异显著,统一周期难以反映真实劣化状态
- 维护经验高度依赖个人,难以规模化复制
其本质原因在于: 维护决策缺乏对设备“真实健康状态”的持续认知能力。
02 预测性维护的核心定位:从“未坏先修”到“健康驱动”
1. 预测性维护的工程定义
预测性维护(Predictive Maintenance, PdM)是指:
基于设备运行状态数据与历史行为,通过模型分析设备健康状态及其变化趋势,在故障发生前识别风险,并在最优时间窗口实施维护干预。
与传统维护方式的本质区别并不在于“是否使用机器学习”,而在于维护决策依据的根本转变。
2. 不同维护模式的范式对比

预测性维护并不是“维护更频繁”,而是让维护发生在“真正需要”的时刻。
03 预测性维护的核心价值:不仅是降本,更是能力升级
1. 工程层价值:让劣化过程可感知
设备故障并非瞬时事件,而是长期劣化过程的结果。预测性维护的核心贡献在于:
- 将微小磨损、失衡、润滑退化等早期变化提前暴露
- 关注趋势演化,而非单点异常
- 避免“拆了才知道好不好”的被动局面
2. 管理层价值:让不确定性可规划
通过对设备健康状态的持续评估,企业能够:
- 将突发停机转化为计划检修
- 协同生产计划、检修窗口与备件准备
- 为维护资源配置提供量化依据
预测性维护的本质,是将不可预测风险转化为可管理的风险区间。
3. 生命周期价值:避免过度维护与过度消耗
- 防止健康设备因周期性检修被过度干预
- 防止隐患设备在高负载下被持续消耗
- 延长关键资产的有效使用周期
04 设备健康如何被“感知”:从信号到健康状态的形成过程
1. 设备健康不是单一参数
“设备健康”并不是某一个传感器读数,而是对以下能力的综合描述:
- 在当前工况下的稳定运行能力
- 性能偏离设计状态的程度
- 失效风险随时间的变化趋势
因此,预测性维护的关键不是“是否报警”,而是健康状态是否在持续劣化。
2. 状态感知的技术路径
(1)多源状态信号采集
预测性维护通常采集以下类型的数据:
振动信号:对轴承、齿轮、转子类故障高度敏感
温度信号:反映摩擦、润滑不良、热异常
声学信号:捕捉早期异常声发射
电流与功率信号:反映负载变化与效率下降
压力、流量等工艺参数:反映堵塞、泄漏等问题

这些信号是“表征变量”,而非健康结论本身。
(2)工况识别与数据治理
设备状态必须在可比工况下分析:
a.区分启停、稳态、负载变化
b.剔除工艺波动带来的干扰
c.对高频、低频信号进行分层处理
这是预测性维护能否“看懂数据”的关键一步。
(3)特征工程与健康指标构建
通过特征工程,将原始信号转化为与失效机理相关的指标:
a.时域特征:RMS、峭度、峰值因子
b.频域特征:频谱峰值、频带能量
c.时频特征:小波变换、包络分析
d.趋势特征与异常特征
在此基础上,构建:
a.健康指数(Health Index, HI)
b.劣化趋势曲线
c.风险水平区间
05 预测性维护的技术原理:机理模型 × 机器学习
1. 为什么不能只靠算法?
在工业现场,工况变化复杂、样本不均衡,纯数据模型容易失效。因此:
机理模型用于约束分析边界、解释状态变化
数据模型用于捕捉复杂非线性关系
二者结合,构成稳定、可解释的预测性维护体系。
2. 常见模型在预测性维护中的角色
传统机器学习(RF、XGBoost) 适合结构化数据、可解释性强、易落地
深度学习(LSTM、CNN) 适合长时序数据与复杂模式识别
无监督模型(孤立森林、自编码器) 适合缺乏故障标签的异常检测场景
模型的目标不是“预测哪天坏”,而是判断风险是否在加速累积。
06 预测性维护系统的工程结构与能力演进
在工业场景中,预测性维护并不是一个单点模型,而是一套分层协同的工程系统。理解其系统结构,是理解后续 AI Agent 必然性的前提。
1. 预测性维护的典型系统分层
从工程实现角度,一套完整的预测性维护系统通常包含以下五个层级:
(1)感知与采集层(Perception Layer)
各类状态传感器(振动、温度、声学、电流、压力等)
采集设备运行的原始物理信号
强调连续性、稳定性与时间一致性
(2)数据与特征层(Data & Feature Layer)
数据清洗、去噪、同步与工况切分
特征工程(时域 / 频域 / 时频域 / 趋势特征)
构建设备状态的“可分析表示”
(3)状态评估与预测层(Analytics Layer)
健康指数(HI)计算
劣化趋势建模
剩余可用寿命(RUL)或风险区间评估
模型可能包含机理模型、统计模型与机器学习模型的组合
(4)诊断与策略层(Diagnosis & Strategy Layer)
将模型输出与失效模式(FMEA)进行关联
判断风险类型、严重程度与发展速度
形成维护策略建议(是否维护、何时维护、关注部位)
(5)执行与管理层(Execution Layer)
对接 EAM / CMMS / 工单系统
推动维护计划、资源协调与结果反馈
形成运维管理闭环
需要注意的是: 大多数预测性维护系统,往往停留在第 3 层或第 4 层,无法真正“驱动行动”
2. 系统瓶颈:从“能预测”到“能执行”的断层
在实际落地中,预测性维护常见一个结构性问题:
模型能够输出健康指数、风险评分、异常趋势
但这些结果以图表、看板或报表形式存在
运维人员需要人工解读、判断、再决策
当设备数量从 10 台 → 100 台 → 1000 台 时,这种模式会迅速失效:
人工监控不可扩展
决策响应滞后
预测价值无法规模化释放
正是在这一断层位置,引入了 AI Agent 的工程必要性。
07 AI Agent:预测性维护系统的“主动执行层”
- AI Agent 出现的工程背景
在预测性维护系统中,AI Agent 并不是“更聪明的算法”,而是为了解决一个明确问题:
谁来持续理解模型结果,并将其转化为可执行的运维行为?
因此,AI Agent 的本质角色是: 预测性维护系统中的“智能调度与决策代理层”。
- 工业预测性维护中的 AI Agent 技术定位
在系统结构中,AI Agent 位于:
状态评估 / 诊断层 与 执行管理层 之间
其核心职责不是“预测”,而是:
理解预测结果
判断行动条件
推动流程执行
从工程视角看,AI Agent 更接近一个具备认知能力的控制与协同单元。
- AI Agent 的内部技术构成(非概念版)
一个可落地的预测性维护 AI Agent,通常包含以下能力模块:
(1)状态感知与上下文理解
接收设备健康指数、趋势斜率、风险评分
结合当前工况、负载、生产计划
理解“当前异常是否具备行动意义”
例如: 同样的振动上升趋势,在高负载短期运行与长期稳态运行下,其维护意义完全不同。
(2)规则 + 模型的混合决策机制
AI Agent 并不依赖单一模型,而是结合:
预测模型输出(趋势、概率、区间)
工程规则(阈值、失效模式、工艺约束)
运维策略(关键设备优先级、检修窗口)
形成可解释、可控的决策逻辑。
(3)行动触发与流程编排能力
当满足条件时,AI Agent 可:
主动触发进一步诊断
推送维护建议(而非原始指标)
生成或建议工单
标记设备维护优先级
这一过程不依赖人工轮询,而是事件驱动。
(4)反馈与自适应调整
接收维护执行结果
校正模型判断偏差
调整阈值与策略参数
从而形成预测—执行—反馈的闭环。
4. AI Agent 与传统系统的本质差异
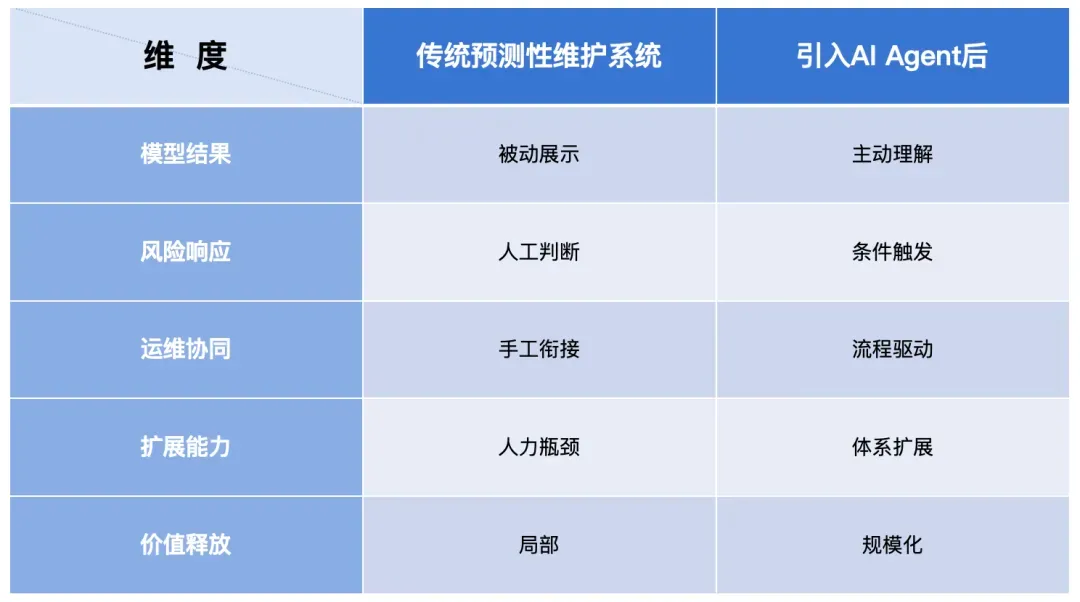
08 从系统能力角度重新理解预测性维护
至此可以看到:
预测性维护 ≠ 算法模型 AI Agent ≠ 更高级的预测算法
二者的关系是:
预测性维护解决“看清设备健康状态” AI Agent 解决“如何基于健康状态持续行动”
只有当预测性维护系统完成从“感知 → 评估 → 决策 → 执行”的完整闭环,其技术价值才能真正转化为运营能力。
09 总结:预测性维护的终极形态
从技术演进角度看,预测性维护正在经历三个阶段:
状态可视化阶段:看到数据
风险可评估阶段:理解趋势
行动可自动化阶段:驱动决策
AI Agent 并不是额外附加,而是第三阶段的必然产物。
其意义不在于“更智能”,而在于:
让预测性维护从“辅助工具”,进化为“主动运维能力”。






